原理部分
如果不想看我啰里啰嗦讲原理的童鞋,可以直接跳到代码部分哦
假定我们要为以下的文字提取关键词,原文来自朱自清先生的《背影》:
我说道,“爸爸,你走吧。”他望车外看了看,说,“我买几个橘子去。你就在此地,不要走动。”我看那边月台的栅栏外有几个卖东西的等着顾客。走到那边月台,须穿过铁道,须跳下去又爬上去。父亲是一个胖子,走过去自然要费事些。我本来要去的,他不肯,只好让他去。我看见他戴着黑布小帽,穿着黑布大马褂,深青布棉袍,蹒跚地走到铁道边,慢慢探身下去,尚不大难。可是他穿过铁道,要爬上那边月台,就不容易了。他用两手攀着上面,两脚再向上缩;他肥胖的身子向左微倾,显出努力的样子。这时我看见他的背影,我的泪很快地流下来了。我赶紧拭干了泪,怕他看见,也怕别人看见。我再向外看时,他已抱了朱红的橘子望回走了。过铁道时,他先将橘子散放在地上,自己慢慢爬下,再抱起橘子走。到这边时,我赶紧去搀他。他和我走到车上,将橘子一股脑儿放在我的皮大衣上。于是扑扑衣上的泥土,心里很轻松似的,过一会说,“我走了;到那边来信!”我望着他走出去。他走了几步,回过头看见我,说,“进去吧,里边没人。”等他的背影混入来来往往的人里,再找不着了,我便进来坐下,我的眼泪又来了。
朱自清先生是我非常崇敬的一位作家,我非常喜欢他的作品。但是问题来了,计算机是没有情感的,他怎么能读懂这几段文字并提取关键词呢?
首先,我们需要计算机进行一个叫分词的操作,就是把文章按照一定的规则进行切分,切成一个一个的短语。分词的算法非常复杂,这里不作过多的阐述,有兴趣的朋友可以上网搜下相关的资料。
分词后我们要想个问题,是不是某一段中经常出现的词,是不是作者非常强调的词呢,那成为关键词的机会是不是越大呢。这里我们就要引入一个叫词频(TF)的概念了:
$$ TF = 某个词在文档中的出现次数 $$
好了,讲到这里我们需要思考一个问题,像上面的文章中,有很多的“的”、“地”这样的结构助词,出现的频率相当高,我们怎么处理呢。工业界和学术界在处理语料数据的时候,会称这些词为“停用词”,字面意思,就是我们在处理语料的时候,忽略掉这些词。常见的做法会在分词的时候,建立停用词词典,直接把这些词从文档中去掉。
然后,获得了词频,你会有疑问了,那是不是直接把词频最高的Top10或者Top5作为关键词不就行了吗,为啥这算法还有个叫逆文档频率的东西啊….
你想想啊,什么是关键词啊,关键词就是某个文档独有的一些词语,而不是每篇都有的。也就是比如某个词在文档A出现了,在BCD没出现,那么我们很大的几率就认为这个词是文档A的关键词。这个时候,登登登登,逆文档频率就出现了:
$$ IDF = log(\frac{语料库中文档的总数}{语料库中包含该词语的文档数+1}) $$
这里我们有个概念,语料库 Corpus。语料库是指一个非常庞大的自然语言数据集合,里面有大量的文章语料可以供计算机使用。我们话说回来,观察上面的式子,因为语料库中包含该词语的文档数是分子,所以如果包含某个词语的文档越少,他的IDF值会越高,那么这个词语很有可能就是这些文档的关键词。有同学观察到分母有个1,这个是为了避免没有任何一篇文章包含这个词导致了分母为0的情况!
好了,我们讲到这里,我们发现词频越高的词越有可能成为关键词,逆向文档频率越高的词越有可能代表这个文档呢。引用高中数学的话,TF,IDF都与某个词是不是关键词的概率成正比关系。那好办,我们把两个值乘起来,作为某个词在某个文档中的频率。对于词语Wi,我们规定其TF-IDF值为:
$$ TF-IDF_i = TF_i \times IDF_i $$
有句话叫“光说不练假把式”,我们就以前面引用的朱自清先生的段落为例,我们以朱自清先生的这篇《背影》作为语料库,每个自然段作为一个文档;使用分词器,抽取里面的名词、动词和形容词进行分析,分析得到这样的数据:
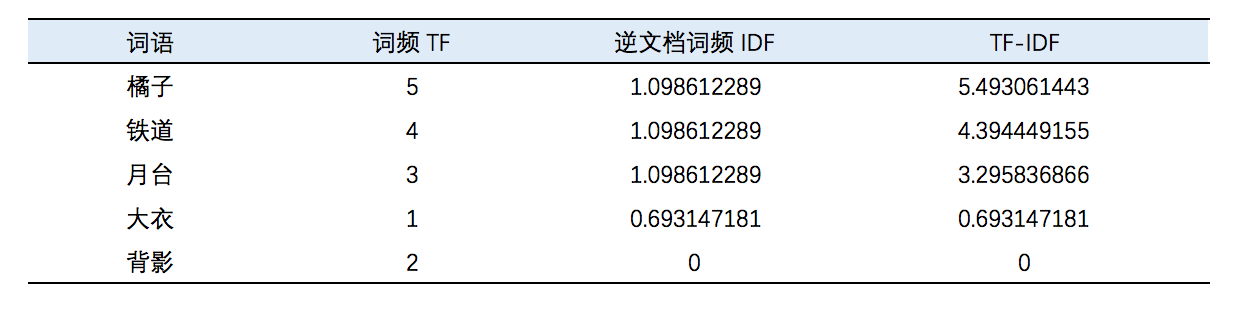
可以看到表格中,这一个自然段橘子的出现频率非常高,而其逆文档频率也相当高,因此“橘子”是这一段的一个关键词。然后“背影”由于在多个自然段都出现了,因此其逆向文档频率就非常低了,近乎为0,因此背影不能作为这一段的一个关键词。因此我们可以指定这段的关键词可以是“橘子”,“铁道”和“月台”等。也大致满足了这一段的主题:父亲越过铁道为作者买橘子,引发了作者的深思。
其实,如果读过小学语文课本的同学都会说,这一段,不是父亲的背影才是引发作者深思的点吗,为什么没有在关键词里。这里有一个非常不严谨的点,我们在技术TF-IDF时,使用的语料集非常狭隘,仅仅是这篇文章,这篇文章的主题恰恰就是“背影”啊,这么多年的语文课告诉我们,作者需要不断进行点题强调,因此造成了IDF低的问题。如果我们的语料库足够丰富,而且我们分析的不仅仅是一个自然段,是一整篇的《背影》我相信效果会更加理想的。
说了那么多的原理,我们就来说说Java怎么可以实现TF-IDF算法(单机版哦~):
Java实现部分
Java部分我们需要使用到Ansj分词器进行分词
Ansj分词器的Github:传送门
使用Maven的同学可以使用:
1
2
3
4
5
6
7
| <dependencies>
<dependency>
<groupId>org.ansj</groupId>
<artifactId>ansj_seg</artifactId>
<version>5.1.1</version>
</dependency>
</dependencies>
|
然后代码的实现非常简单,先把代码全部贴出来:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
| public class TfIdfUtil {
private List<String> documents;
private List<List<String>> documentWords;
private List<Map<String,Integer>> docuementTfList;
private Map<String,Double> idfMap;
private boolean onlyNoun = false;
public TfIdfUtil(List<String> documents) {
this.documents = documents;
}
public List<Map<String,Double>> eval(){
this.splitWord();
this.calTf();
this.calIdf();
return calTfIdf();
}
private int getDocumentCount() {
return documents.size();
}
private void splitWord() {
documentWords = new ArrayList<List<String>>();
for( String document : documents ) {
Result splitWordRes = DicAnalysis.parse(document);
List<String> wordList = new ArrayList<String>();
for(Term term : splitWordRes.getTerms()) {
if(onlyNoun) {
if(term.getNatureStr().equals("n")||term.getNatureStr().equals("ns")||term.getNatureStr().equals("nz")) {
wordList.add(term.getName());
}
}else {
wordList.add(term.getName());
}
}
documentWords.add(wordList);
}
}
private void calTf() {
docuementTfList = new ArrayList<Map<String,Integer>>();
for(List<String> wordList : documentWords ) {
Map<String,Integer> countMap = new HashMap<String,Integer>();
for(String word : wordList) {
if(countMap.containsKey(word)) {
countMap.put(word, countMap.get(word)+1);
}else {
countMap.put(word, 1);
}
}
docuementTfList.add(countMap);
}
}
private void calIdf() {
int documentCount = getDocumentCount();
idfMap = new HashMap<String,Double>();
Map<String,Integer> wordAppearendMap = new HashMap<String,Integer>();
for(Map<String,Integer> countMap : docuementTfList ) {
for(String word : countMap.keySet()) {
if(wordAppearendMap.containsKey(word)) {
wordAppearendMap.put(word, wordAppearendMap.get(word)+1);
}else {
wordAppearendMap.put(word, 1);
}
}
}
for(String word : wordAppearendMap.keySet()) {
double idf = Math.log( documentCount / (wordAppearendMap.get(word)+1) );
idfMap.put(word, idf);
}
}
private List<Map<String,Double>> calTfIdf() {
List<Map<String,Double>> tfidfRes = new ArrayList<Map<String,Double>>();
for(Map<String,Integer> docuementTfMap : docuementTfList ) {
Map<String,Double> tfIdf = new HashMap<String,Double>();
for(String word : docuementTfMap.keySet()) {
double tfidf = idfMap.get(word) * docuementTfMap.get(word);
tfIdf.put(word, tfidf);
}
tfidfRes.add(tfIdf);
}
return tfidfRes;
}
}
|
首先在TfIdfUtil类实例化的时候,我们需要传入一个List,List的每一个字符串元素都一个文档。
然后,执行eval()方法
eval()方法的执行流程是这样的
首先执行 splitWord() 进行分词 -> 执行 calTf() 计算每个分析的词频 -> 执行calIdf()计算逆向词频 -> 执行 calTfIdf() 计算每个词的TF-IDF
Notes 注意了
为了提高TF-IDF的准确性,可以考虑在分词的时候,向分词器提供停用词表和自定义分词!!!
啰里啰嗦的部分
有同学问,上述算法到底可不可行的,当然可以了。我所在的天高科技工作室内部工作平台TentcooTools已经应用了TF-IDF对每一篇的同学周报进行关键词抽取操作,并且这个关键词抽取目测还是挺准的。工作室17年的年度关键词也是通过这个算法生成的。