状态!状态!
在 Flink 的官网中,我们可以看到 Flink 社区对于 Flink 的定义是 Apache Flink® — Stateful Computations over Data Streams, 一个在数据流之上的有状态计算引擎。在正式开工之前,我们需要先对于状态有一个很初步很初步的了解。 Flink 官网上对于 State 有非常多专业的解释,我今天先初步在本文里面先谈谈简单的一些理解,感兴趣的朋友呢可以去读读 Flink 官方的解释。
在 Flink 中,任务是使用有向无环图进行描述的,每个图的节点实际上是一个操作函数或算子(Operator),而这些函数和算子在 Flink 处理单一的元素和事件时会存储数据(官网使用的是 remember 记住),因此我们可以说 Flink 的算子和函数是有状态的(Stateful)。状态在Flink中非常重要,我会在后面单独谈谈 Flink 的状态。
何为流
我们在学习程序设计的过程中,会接触到各种各样的流,文件流,网络流,Java 的流 API 等等等等。在 Flink 的世界里,数据可以形成事件流,日志记录,传感器数据,用户的行为等等都可以形成数据流。Flink 官网 中把流分为两类:有界流和无界流。
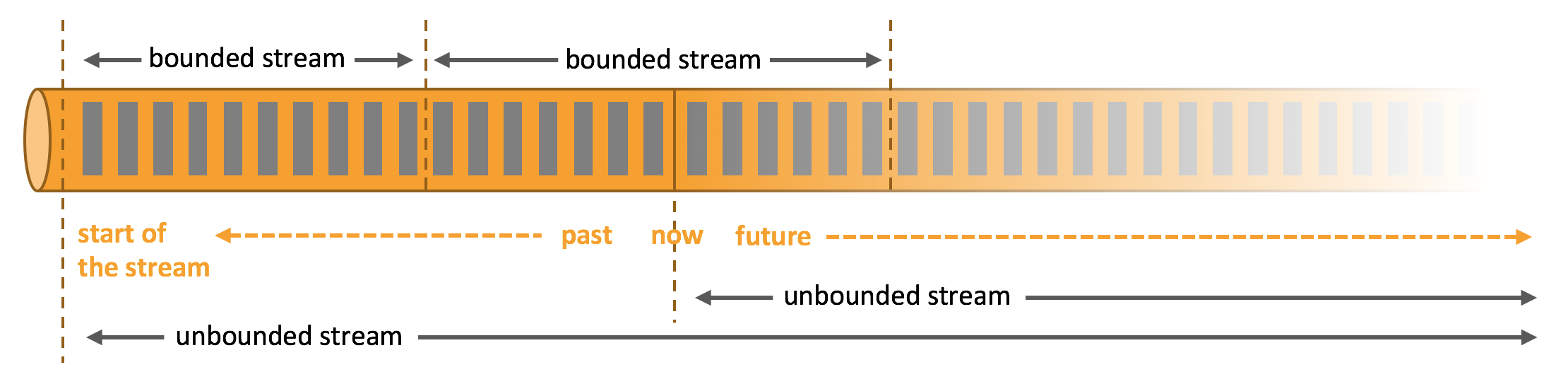
简单来说,无界流有流的起点但是没有终点,数据源源不断地到达,因此我们也需要持续地处理数据。而有界流是有流的结束点的,且数据可以在全部到达后进行处理,因此我们可以把有界流理解为批处理(Batch)。与真正的批处理有所不同的是,Flink是有状态的,每个状态中的数据可能会随着数据的不断到达而发生变化。值得注意的是,由于无界流会源源不断地到达,一般我们会使用时间的特征作为无界流的处理顺序。
搭建 Maven 项目
首先创建一个 Maven 项目,并添加以下关键的依赖:
1 | <properties> |
编写 Word Count Job
完成 Maven 后我们需要编写 Word Count 的 任务代码。和普通的 Java 程序一样,Flink 会找到并执行 main 方法中所定义的处理逻辑。首先我们需要在 main 方法的第一句就使用 getExecutionEnvironment() 方法获得程序运行所需要的流环境
1 | StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); |
然后我们需要向流处理的环境注册一个数据源,以源源不断地读入字符串:
1 | DataStream<String> source = env.addSource(new WordCountSource()).name("SteveJobs-Word"); |
在获取到数据源后,我们需要对数据进行处理。首先是需要使用 flatMap 配合分词工具对输入的字符串进行切分,得到多个二元组。这些二元组的第一个元素是所得的单词,而第二个元素是 1 。为什么是 1 呢,因为我们会根据单词进行分组,每个单词都会拥有一个独立的 状态 ,每个状态都会存储当前处理过的数据信息。在这个样例中,flink 会对每个单词的状态中所有元组的第二个元素进行求和操作。由于第二个元素都是1,可知其求和的结果等于单词的个数。
1 | DataStream<Tuple2<String,Integer>> proc = source.flatMap(new TextTokenizer()) |
在 Flink 中,一切的数据都需要输出到 Sink 中。Sink 可以输出数据到数据库,到 Elasticsearch 中,到 HDFS 中,或是到 Kafka MQ 中。因此,我们需要指定 Flink 的计算结果输出位置。如在本样例中,我们会把数据输出到
1 | proc.addSink(new WordCountSink()) |
Flink 的任务需要在本地打包,并上传到服务器加载后才可以在 Flink 集群上运行。因此我们需要在 main 方法的末尾,指定任务的名称,并调用环境的 execute 方法启动任务。
1 | env.execute("Word Count"); |
最终,我们可以得到 WordCountJob 的写法:
1 | public class WordCountJob { |
数据的 Source 和 Sink
在这个项目中,我们先做一个有界流的试验。在 Flink 中,Source 和 Sink 是数据输入和数据输出的算子,即数据通过 Source 算子输入, 通过 Sink 算子输出。根据刚刚所介绍的,有界流实质上是指批处理,所处理的数据是有限的。因此我们的输入数据源部分我们实现了简单的遍历器数据源 (JavaDoc),直接上代码:
1 | public class WordCountSource extends FromIteratorFunction<String> implements Serializable { |
Sink 作为输出,我们参照了 Flink 官方 Code Walkthroughs 的写法,直接输出到日志中。 具体写法可以参考 Sink 的 JavaDoc ,以下是我的写法:
1 | public class WordCountSink implements SinkFunction<Tuple2<String,Integer>> { |
测试
在编写好代码以后,使用 Maven 的指令进行打包:
1 | mvn clean package |
我在之前的更新中介绍了如何搭建单机版 Flink , 传送门 。 我们把单机版 Flink 启动起来,然后选择 Submit New Job ,点击 Add new 通过网页版上传刚刚打包好的包。
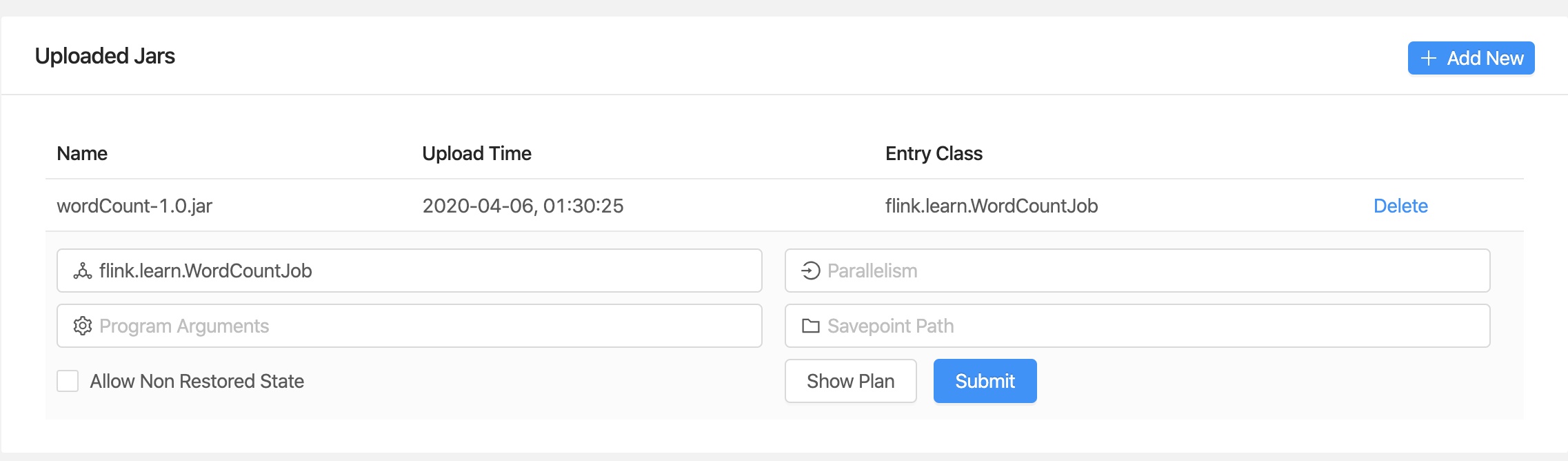
我们可以点击 Show Plan 查看 我们在程序中定义的执行图。
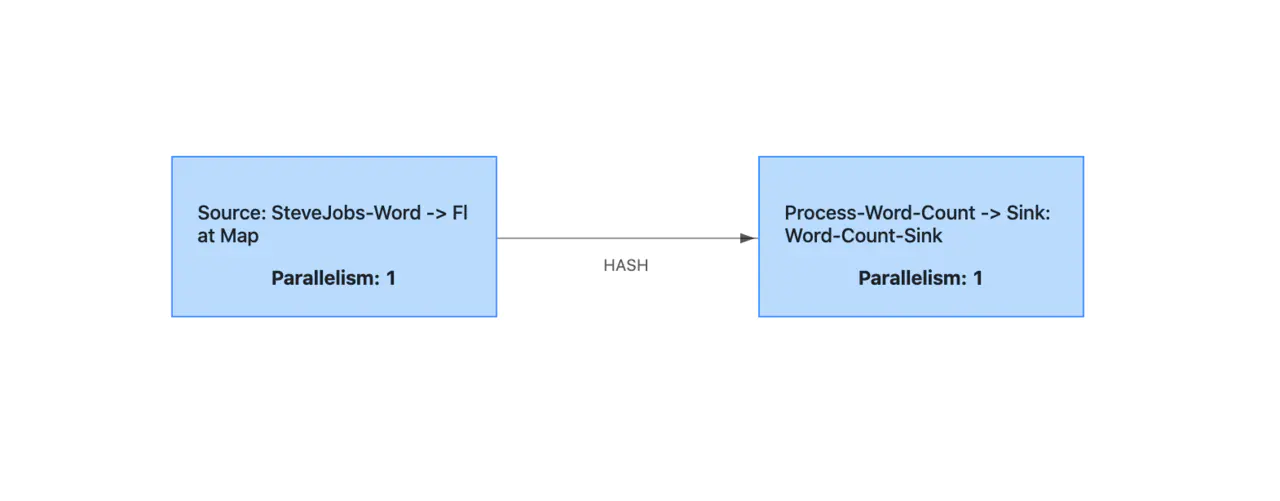
点击 Submit,即可提交任务到 Flink 并执行。我们可以在 Task Manager 中,选择并查看当前执行任务的 Task Manager 的 Log。即可看到我们在 Sink 中输出的日志:

可以看到,单词的统计会随着流数据的输入而不断增长。
每次更新啰里啰嗦的话
我提供了本实验的源代码,请在我的 Github 获取:ousheobin/flink-word-count 。
欢迎大家在上面折腾各种玩法,比如实现无界的数据源,或者把你的 word count 结果输出到 Kafka MQ。